On polarity, distillation,
and the cost of compute.
Preprocessing
We normalised casing, tokenised with nltk, and stripped English stopwords before vectorising for the TF-IDF baseline. Reviews longer than 512 tokens were truncated for transformer input.
import nltk
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
tokens = nltk.word_tokenize(text.lower())
tokens = [t for t in tokens if t.isalpha() and t not in stop_words]
return " ".join(tokens)Architecture
The transformer backbone is DistilBERT — a knowledge-distilled BERT that retains ~97% of the teacher's GLUE score at ~40% the parameter count. We fine-tune it for binary classification, then train a smaller student on its soft outputs.

Results
Three views of the same experiment. The baseline closes most of the gap to the transformer; augmentation closes the rest.
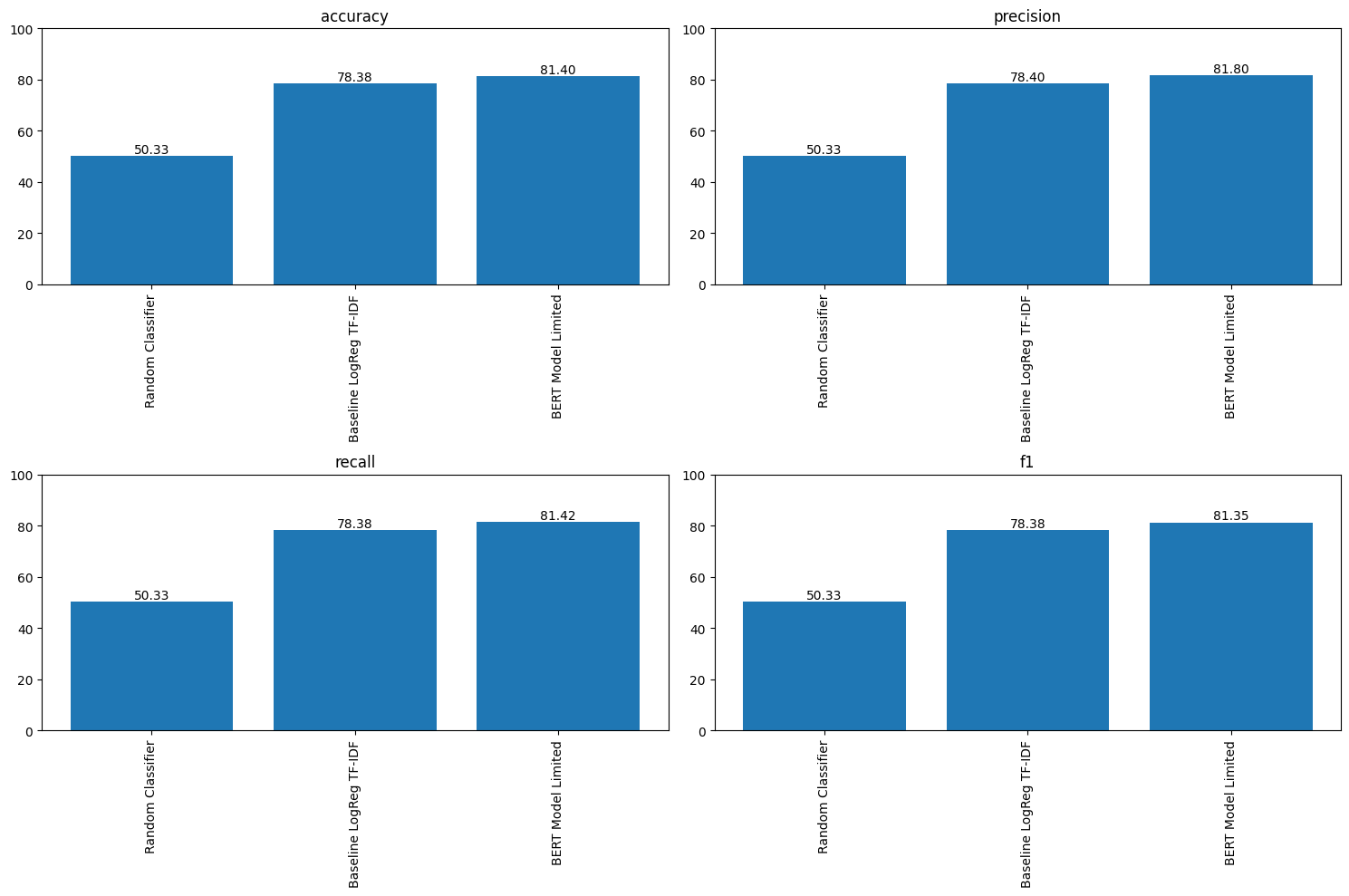
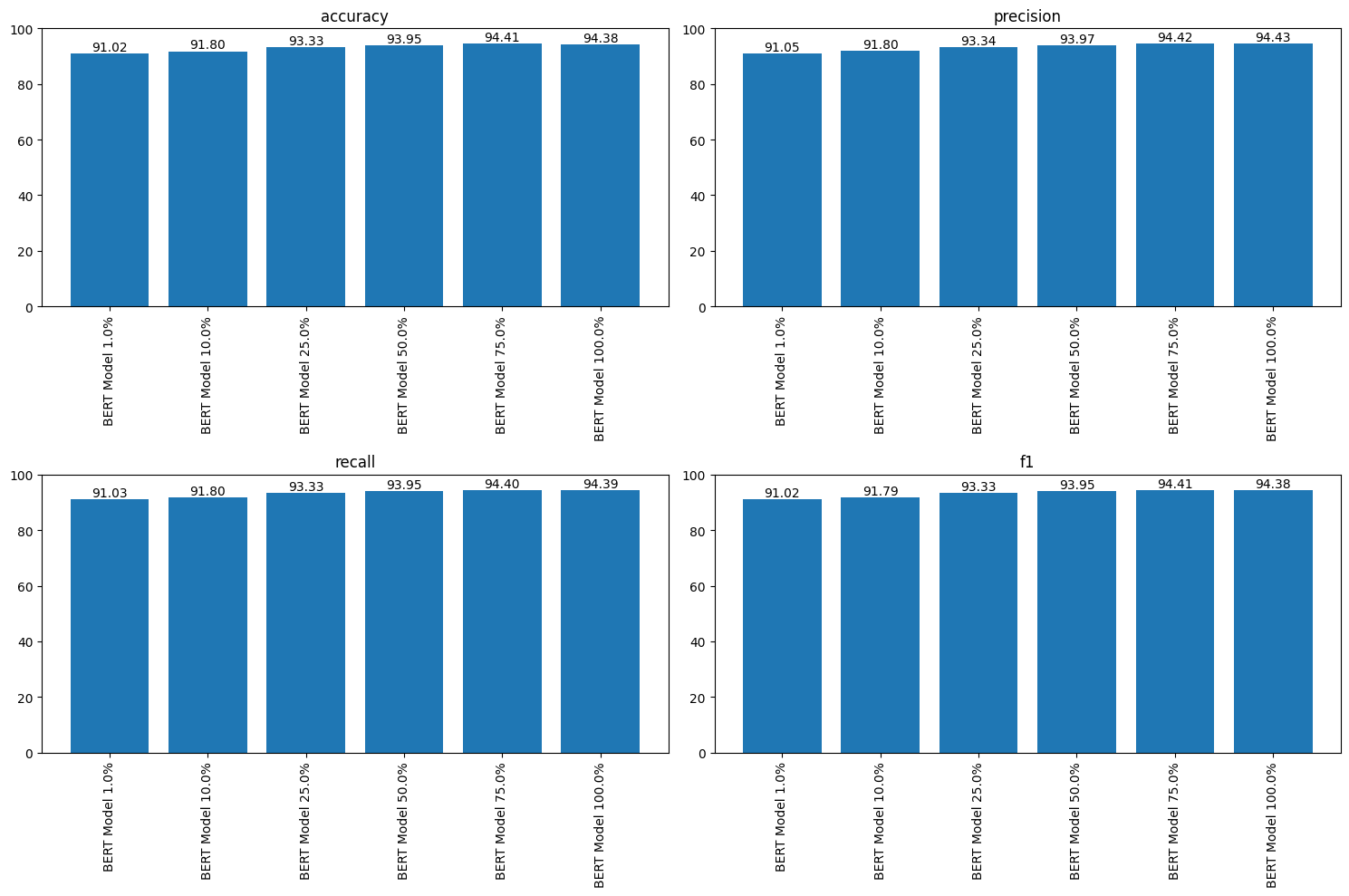
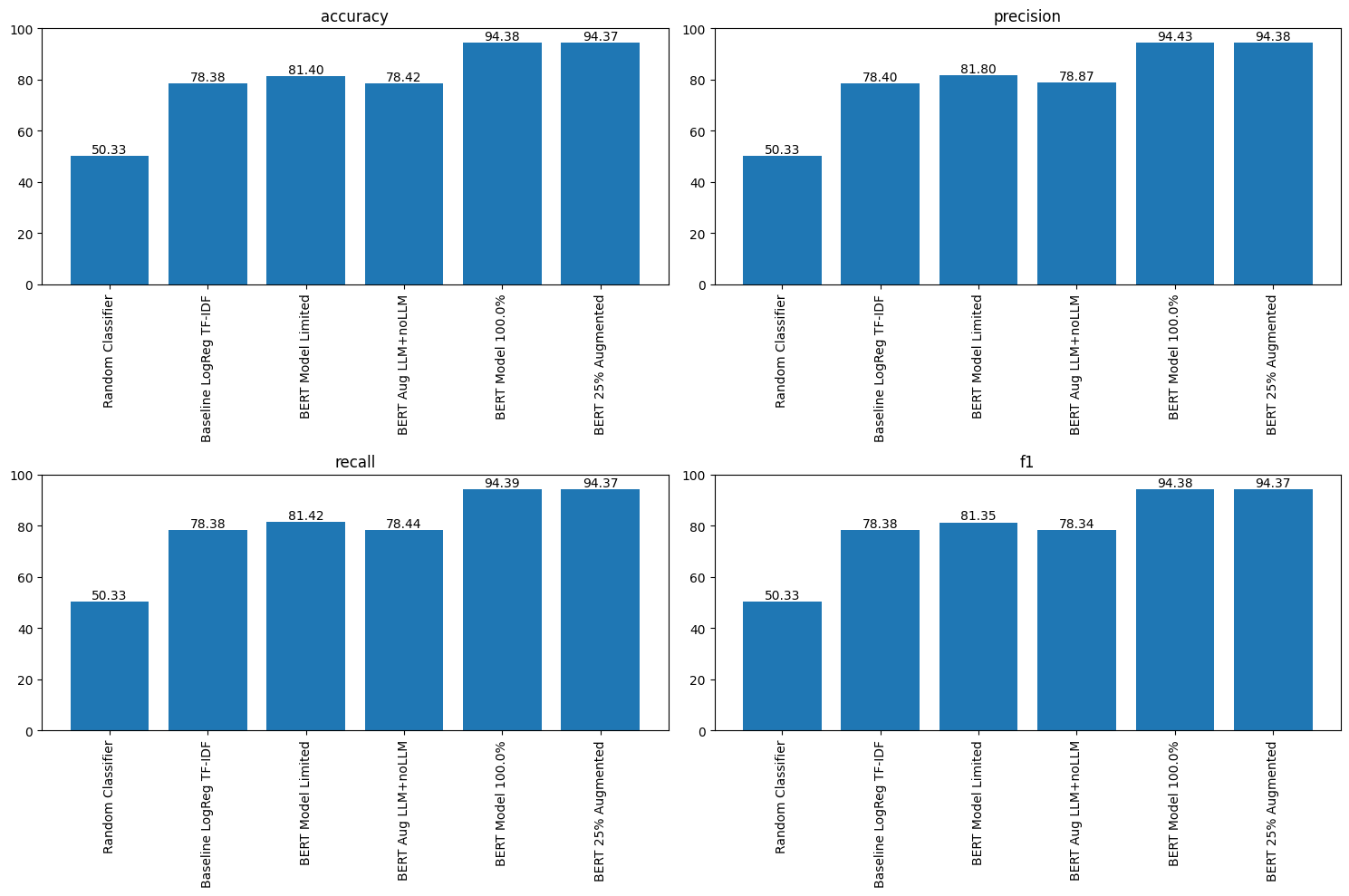
Lessons
Fine-tuning a distilled model on synthetic-augmented data is a surprisingly strong recipe when compute is constrained. A nested distillation (student-of-student) recovered most of the teacher's accuracy while cutting inference cost by roughly six-fold — useful when the target is a laptop or an edge device, not a datacentre.