NLP · Political Text · 2024
Party labels
from speech alone.

Results
The per-class predicted-probability distributions below are diagnostic. For the two pairs the model was trained on (PSOE/PP and Podemos/Vox), the densities separate cleanly toward 0 and 1 — the model knows what each party sounds like. For ERC/JxC — two Catalan pro-independence parties not seen at training time — the densities overlap heavily, correctly reflecting that their rhetoric is less separable.
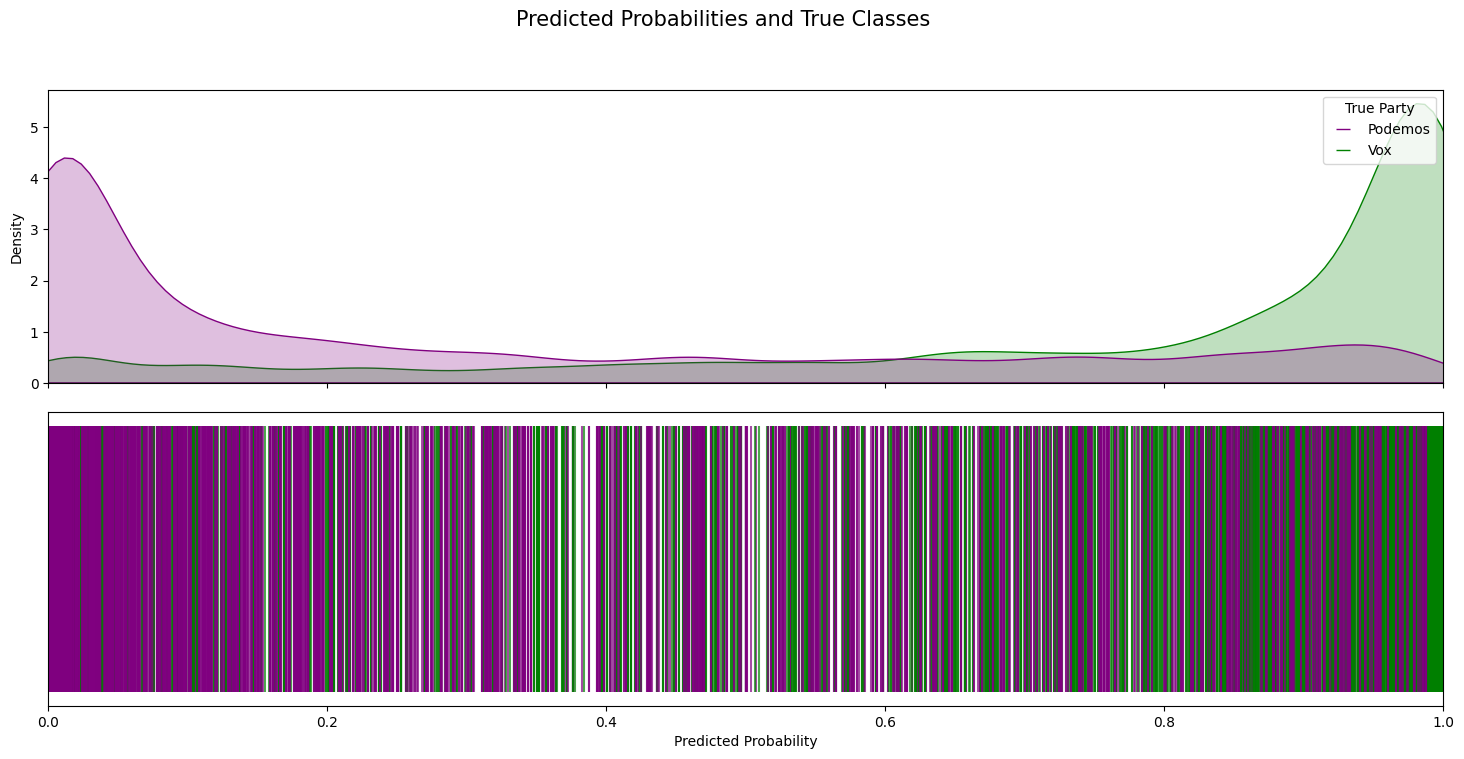
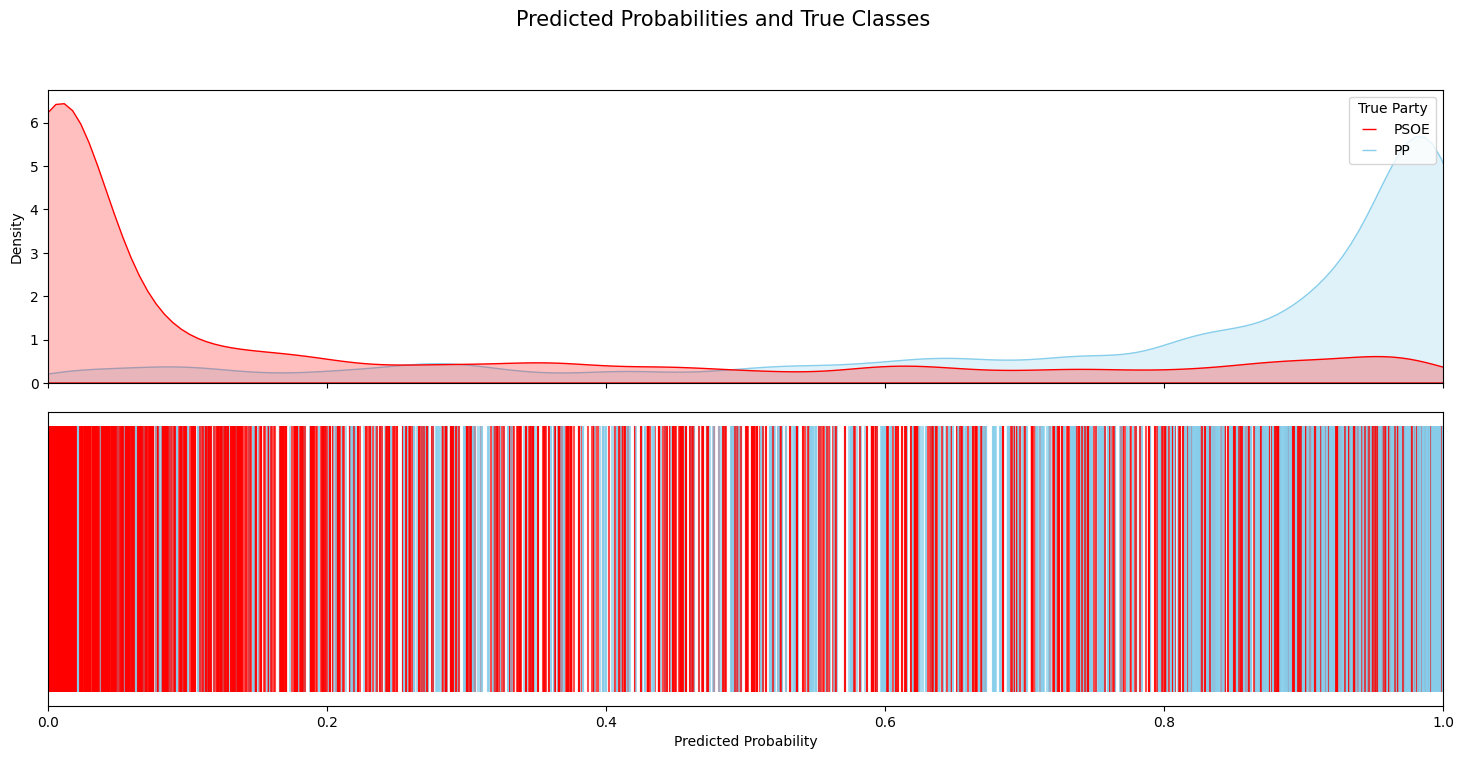
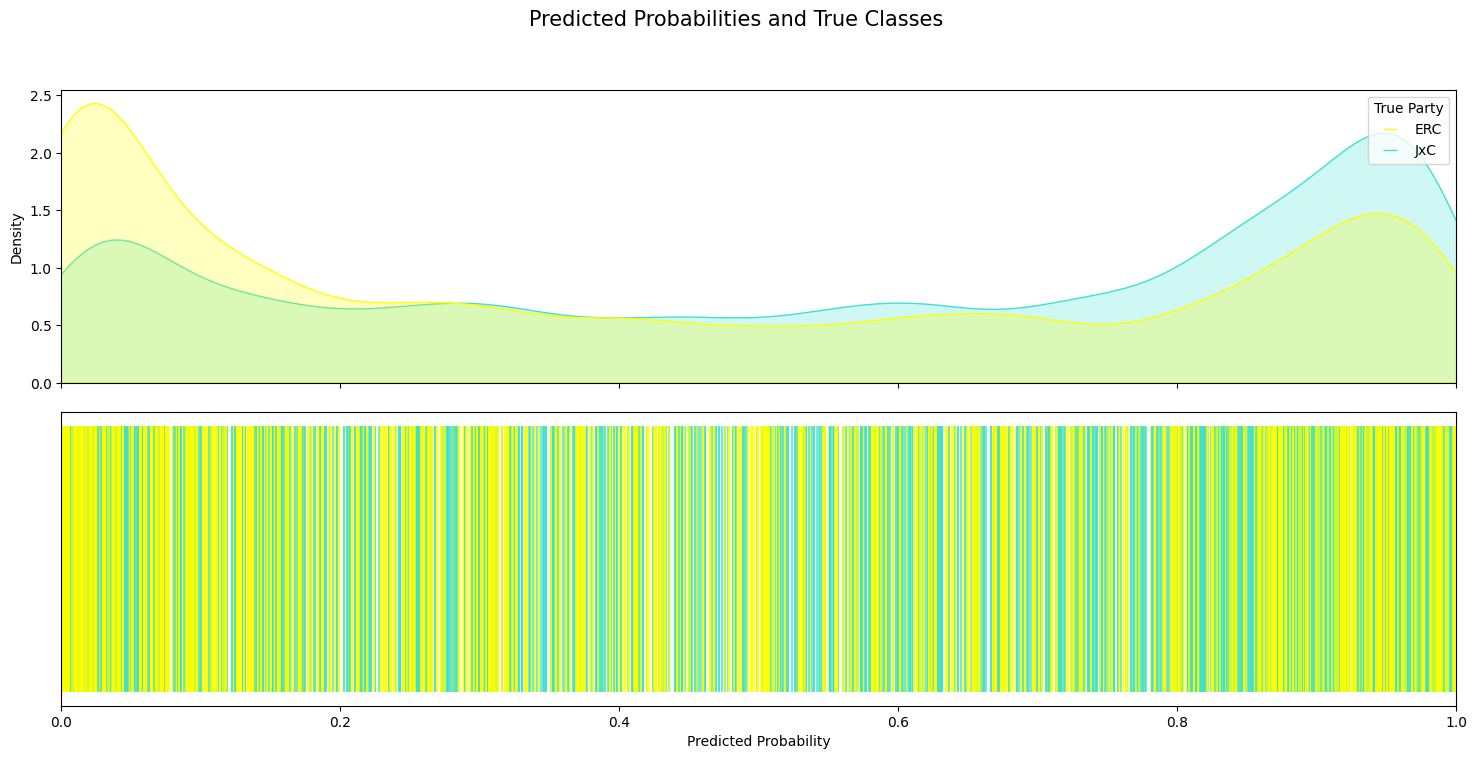
Lessons
Classifiers trained on ideologically distant parties transfer partially to out-of-distribution parties, and the amount of transfer is itself a measurement: low class-separation probabilities on unseen pairs tells us something substantive about rhetorical proximity.