
Overview
This project tackles binary sentiment classification on a sampled Amazon review dataset, comparing traditional baselines with advanced transformer-based models. It explores methods such as TF-IDF logistic regression, fine-tuned DistilBERT with data augmentation (using both synonym replacement and LLM-generated data), zero-shot learning, and model distillation (yes, we further distilled our model from an already distilled model, computational resource limits are humorous sometimes) to balance accuracy and efficiency, achieving performance levels close to state-of-the-art.
We performed an extensive exploration and practical application of sophisticated Natural Language Processing (NLP) techniques aimed at classifying Amazon product reviews based on sentiment polarity, specifically identifying whether reviews express positive or negative opinions. Beyond merely striving for high classification accuracy, we also aimed to uncover deeper insights into the underlying behaviors and decision-making processes exhibited by various models throughout their execution. 📚🔍💬
The project started with a methodical and structured workflow, emphasizing comprehensive data preprocessing to manage the inherently noisy and unstructured textual data. This phase involved meticulous normalization, accurate tokenization of sentences, careful handling of stop words, and standardization of the textual format. 🧹🔧📋
During the exploratory stage, significant attention was given to experimenting with diverse modeling approaches, prominently featuring advanced and widely recognized algorithms such as Logistic Regression, and cutting-edge Transformer-based models, specifically DistilBERT (a distilled version of BERT, since the full model was too large for our computational resources at the time). The iterative nature of training and validation phases required rigorous assessment of each model’s performance using well-established metrics such as accuracy, precision, recall, and F1 score. It must be noted that even though it’s important to monitorize the performance of the model across most of these metrics, in this particular case, there was very little variation since the initial dataset contained high quality data and was already balanced. 📊🤖⚙️
Discussion of the Results 📌📉📈
Throughout the various modeling approaches tested, Logistic Regression already showed somewhat competitive accuracy, providing quick baseline result (alongside a simple random classifier as an ultra naive baseline). However, the introduction and fine-tuning of the Transformer-based model DistilBERT, significantly increased the predictive capabilities. DistilBERT is optimized for computational efficiency without considerable performance sacrifice with respect to the full BERT model. This balance highlighted the importance of selecting suitable models aligned with computational constraints and project goals (we sort of learned this the hard way after trying to run a full BERT model overnight and failing miserably).
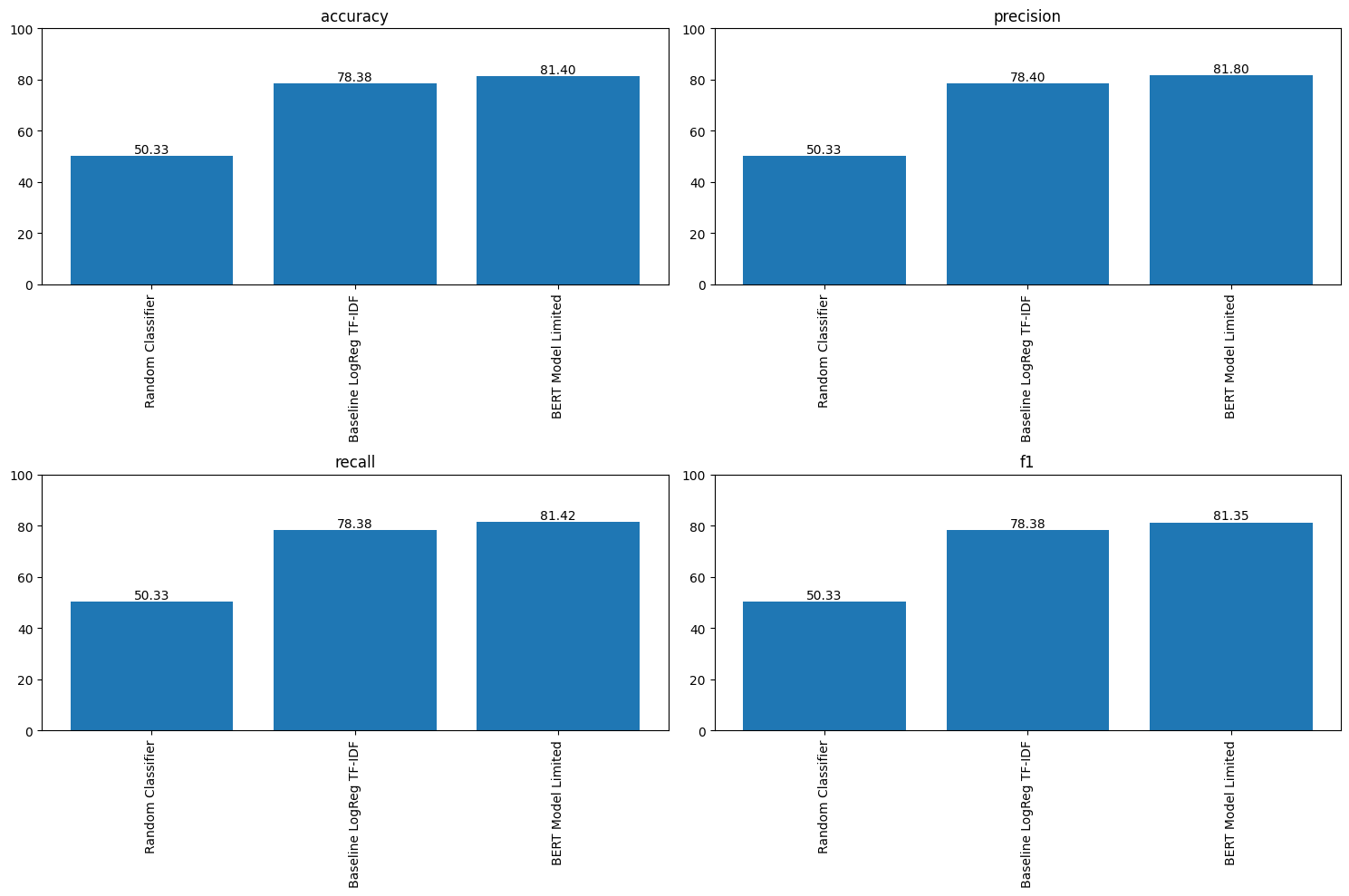
The comparative performance analysis highlighted in the graph below demonstrates the improvements obtained from the Random Classifier to the BERT-based model (albeit in that case the scores are for DistilBERT being fine-tuned only on a subset of 32 labeled reviews). The consistent enhancement across accuracy, precision, recall, and F1 scores clearly illustrates the advantage of sophisticated Transformer-based models over traditional methods, even with extremely small training datasets.
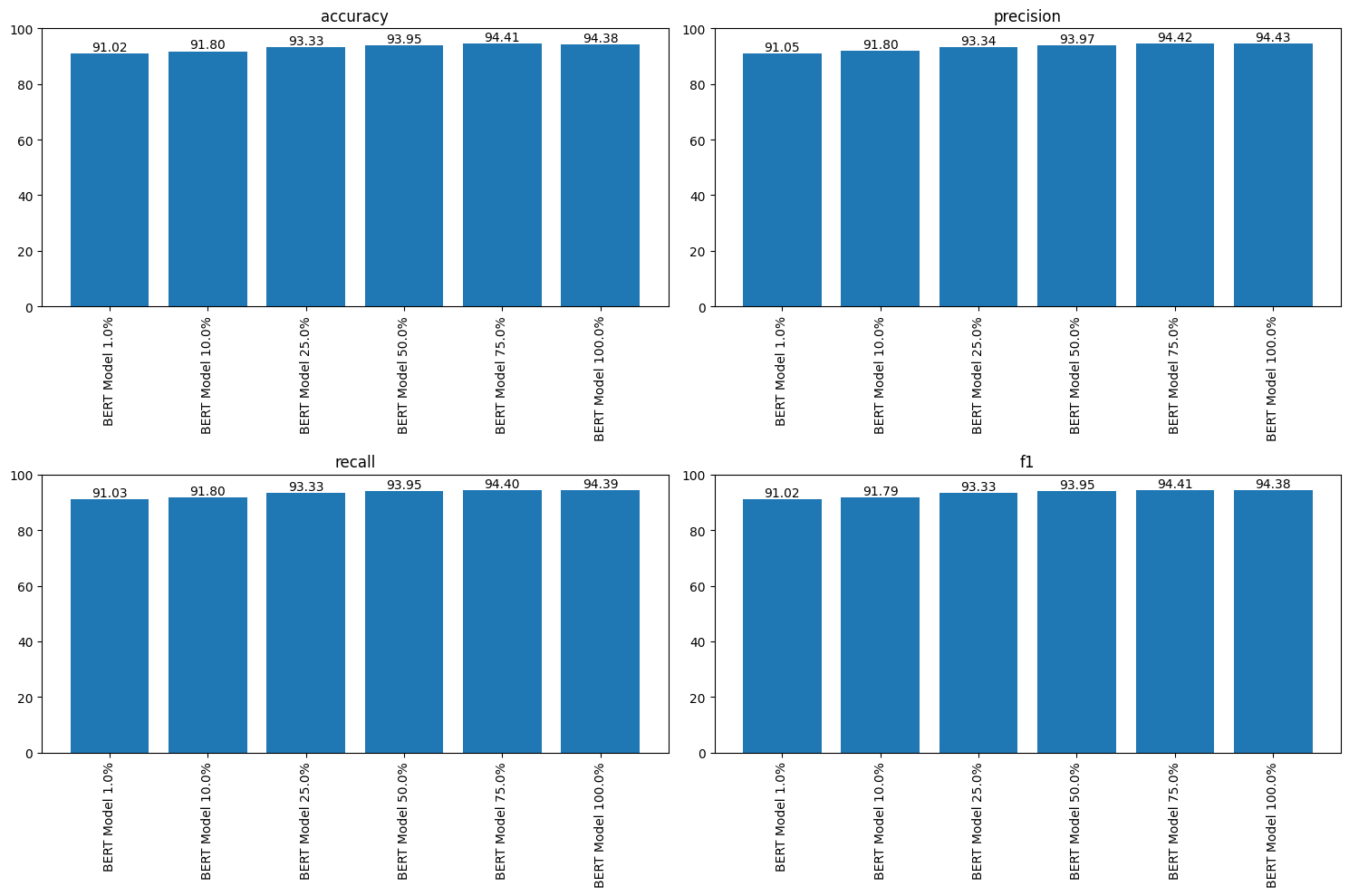
Further analysis, presented in the graph below, investigates the relationship between training data volume and model performance using DistilBERT. These results emphasize the significant gains in accuracy and other metrics as more data was introduced, underscoring the value of adequate training volume for deep learning models. Bear in mind that, in our case, even 1% of the full dataset meant using already thousands of reviews to fine-tune the model. As you can appreciate, the performance increase from 32 to thousands of reviews used in the training phase is significant, but not as much as it might be expected.
Technological Insights 🛠️🔗📲
In conducting the project, we used several crucial technologies. Jupyter Notebooks facilitated interactive experimentation, offering immediate feedback and promoting iterative enhancements. Version control via Git provided essential functionality for collaborative work and systematically documenting progress. Visualization libraries such as Matplotlib and Seaborn were effectively utilized to communicate findings clearly and comprehensively (for example, the graphs presented supra), thus reinforcing analytical insights through visual representation.
Before diving into the use of the Transformers library from Hugging Face, we used several other libraries to perform some initial steps such as tokenization and stop words removal. For those last ones we used libraries such as nltk and stopwords.
Below, find a sample of the preprocessing steps performed on the dataset:
# Import necessary libraries
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
# Tokenization and stop words removal
stop_words = set(stopwords.words('english'))
def preprocess_text(text):
tokens = nltk.word_tokenize(text.lower())
tokens = [token for token in tokens if token.isalpha() and token not in stop_words]
return " ".join(tokens)
Key Takeaways and Lessons Learned 🎯🔑📌
The most impactful lessons from the project emerged through overcoming challenges. Implementing and fine-tuning DistilBERT proved to be notably instructive; mastering its hyperparameter settings and optimizing computational efficiency demanded careful trial and error. This experience underlined the critical value of iterative experimentation, patience, and systematic debugging. These cumulative experiences refined the understanding of best practices in NLP model fine-tuning and the strategic management of complex, computationally intensive tasks.
To confirm the reliability and validity of the models and derived insights, the project actively incorporated multiple peer review methods. Informal feedback from colleagues was regularly sought, complemented by collaborative troubleshooting sessions which proved instrumental in validating results and fine-tuning analytical methods. Constructive criticism was systematically incorporated into the workflow, ensuring that the project maintained alignment with professional standards and contemporary practices within the NLP community. 🗣️👥✅
We soon discovered that converting a large dataset into a tensor suitable for the Transformers framework was a time-consuming endeavor. As a result, each iteration demanded considerable patience.