
Introduction to the Research 🎯
This project investigates whether machine learning techniques can effectively classify political speeches in Spain according to party affiliation, and how such classifications can offer insights into ideological and rhetorical differences between parties. The work is situated at the intersection of Natural Language Processing (NLP) and political science, using speeches from Spain’s national parliament between 2015 and 2023. The ultimate goal is to understand whether the semantics of political discourse align with party lines—and if so, to what extent.
Context and Background 🏛️📚
Since the financial crisis of 2008, the Spanish political system has evolved from a stable two-party system into a complex and fragmented landscape. Alongside the traditional Spanish Socialist Workers’ Party (PSOE) and the Popular Party (PP), new entrants like Podemos, Ciudadanos, and Vox have shifted the ideological balance. This shift provides fertile ground to investigate how different parties express themselves in parliament and whether machine learning models can reliably distinguish between them based solely on language use.
Data Overview and Preprocessing 🔍🗂️
The dataset used originates from the ParlaMint project, which aggregates and annotates parliamentary debate transcripts. The raw data—composed of multiple .tsv and .txt files—required consolidation into a usable DataFrame. After filtering to retain only relevant speeches (e.g., by “diputado/a”), and removing non-informative interventions, the data was processed into four binary classification subsets:
- PSOE vs. PP
- Podemos vs. Vox
- ERC vs. JxCat
- Bildu vs. PNV
To ensure fairness and relevance, we implemented a speaker-level split for training and testing sets. Tokenization, lemmatization, and the removal of common names and party references were executed to avoid model bias. Additionally, speeches were segmented into chunks of approximately 100–300 tokens to standardize length and control for verbosity.
# Example: Token slicing for standardization
from nltk.tokenize import word_tokenize
def segment_speech(text, min_len=100, max_len=300):
tokens = word_tokenize(text)
segments = [" ".join(tokens[i:i+max_len]) for i in range(0, len(tokens), max_len)]
return [seg for seg in segments if len(word_tokenize(seg)) >= min_len]
Modelling Approach 🧠📈
Two classifiers were employed: Random Forest and XGBoost. Both were trained on the PSOE–PP dataset and then evaluated on held-out speakers from the same dataset, as well as on the other political party pairs. This transfer learning setup tested the models’ generalization capabilities across ideological and regional divides.
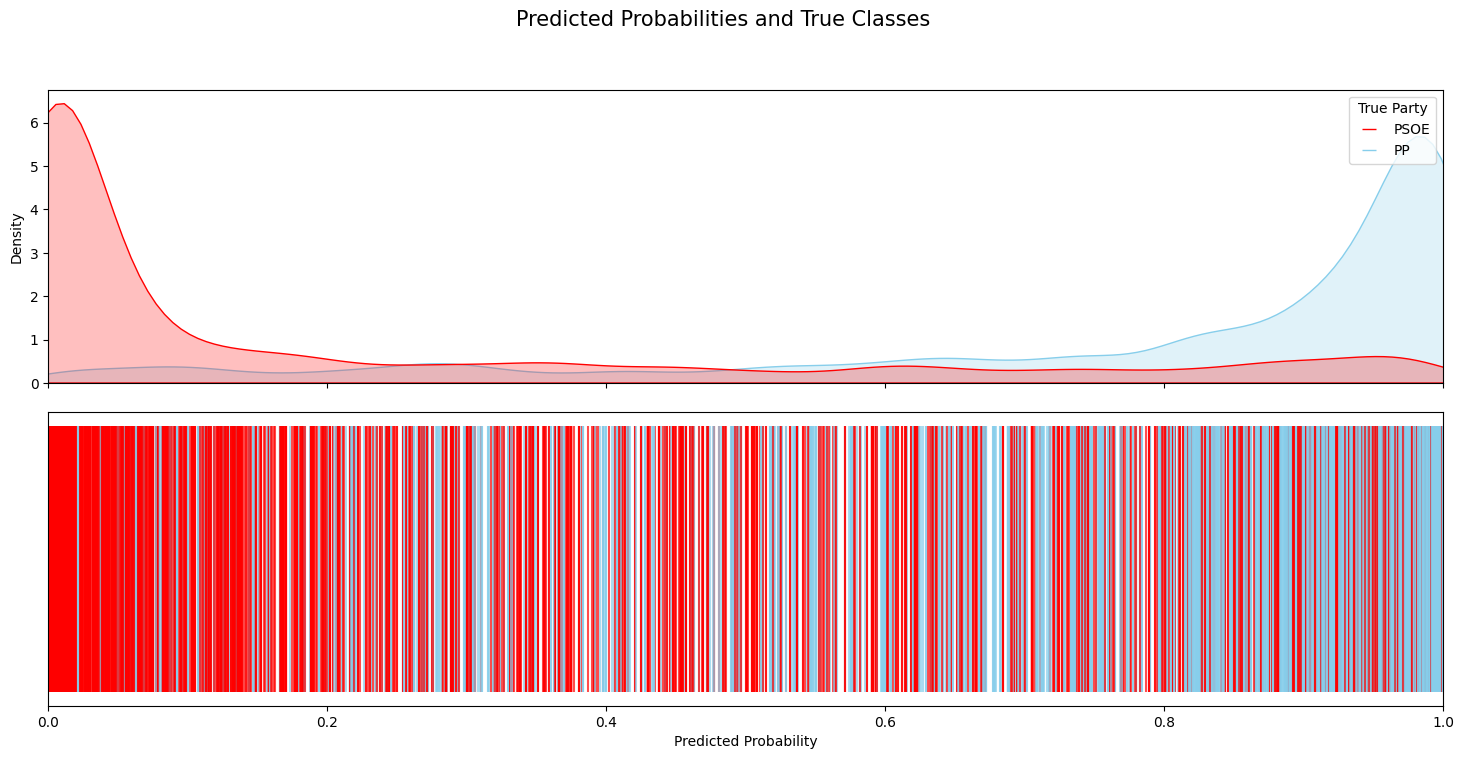
Model predictions were framed probabilistically: a score close to 0 suggested similarity to PSOE-style rhetoric, while scores near 1 indicated alignment with PP rhetoric. The use of both models provided robustness, with Random Forest offering centered predictions and XGBoost delivering more distributed and confident outputs.
Performance and Findings 📊✅
The best model, XGBoost, achieved out-of-sample AUC scores around 0.9 for PSOE–PP classification, indicating strong discriminatory power even when the speakers in the test set had not been seen during training. These results suggest that party-affiliated language is sufficiently distinct for ML models to exploit.
# XGBoost Training Snippet
from xgboost import XGBClassifier
xgb = XGBClassifier(use_label_encoder=False, eval_metric='logloss')
xgb.fit(X_train, y_train)
y_pred_proba = xgb.predict_proba(X_test)[:, 1]
The results were visualized using prediction distribution plots that mimicked a political spectrum. For example, PSOE speeches clustered around 0, while PP speeches gathered near 1. These visualizations reinforced the model’s semantic sensitivity to ideological nuances.
Feature Importances and Interpretation 🧩📝
The top influential n-grams for classification included terms like derecha, ciudadanía, crear empleo, recorte, and independentista. Many of these terms relate to socio-economic policy or political identity. Based on the polarity of these terms in known contexts, it is inferred that left-leaning parties tend to use progressive and collectivist terminology, while right-leaning parties focus on order, national unity, and criticism of the opposing ideology.
| Term 1 | Value | Term 2 | Value | Term 3 | Value |
|---|---|---|---|---|---|
| derecha | 0.038142 | izquierda | 0.004678 | término | 0.002546 |
| ciudadanía | 0.024661 | asunto | 0.004543 | comentar | 0.002514 |
| transformación | 0.011111 | elemento | 0.004511 | proyecto presupuesto | 0.002503 |
| socio | 0.010764 | 2016 | 0.004418 | millón español | 0.002464 |
| crear empleo | 0.008942 | recortar | 0.004065 | convalidación real | 0.002435 |
| cuestión | 0.008694 | ultraderecha | 0.004033 | mundo | 0.002373 |
| evidentemente | 0.008617 | extraordinario | 0.003891 | español española | 0.002241 |
| diputado bien | 0.007627 | digno | 0.003856 | pagar | 0.002240 |
| transición | 0.007456 | destruir | 0.003501 | español tener | 0.002175 |
| respecto | 0.007144 | indicar | 0.003105 | ciudadano ciudadana | 0.002162 |
| creación empleo | 0.006475 | colectivo | 0.003102 | historia | 0.002135 |
| pandemia | 0.006063 | inversión | 0.003018 | periodo | 0.002118 |
| empleo | 0.005920 | ciudadana | 0.002989 | formula | 0.002117 |
| recorte | 0.005070 | amnistía fiscal | 0.002922 | constitución | 0.002065 |
| mayoría absoluto | 0.004873 | 2015 | 0.002893 | tejido productivo | 0.002044 |
| independentista | 0.004827 | propaganda | 0.002889 | trabajador | 0.002038 |
| necesidad | 0.004817 | crecer | 0.002835 |
This insight was further illustrated by speech excerpts. For instance, a Vox speech on national identity was classified similarly to PP, while a feminist Podemos speech aligned with PSOE. These examples highlight the classifier’s ability to map ideological content to party identity, even beyond the training set.
Transfer Learning on Other Party Pairs 🔄🇪🇸
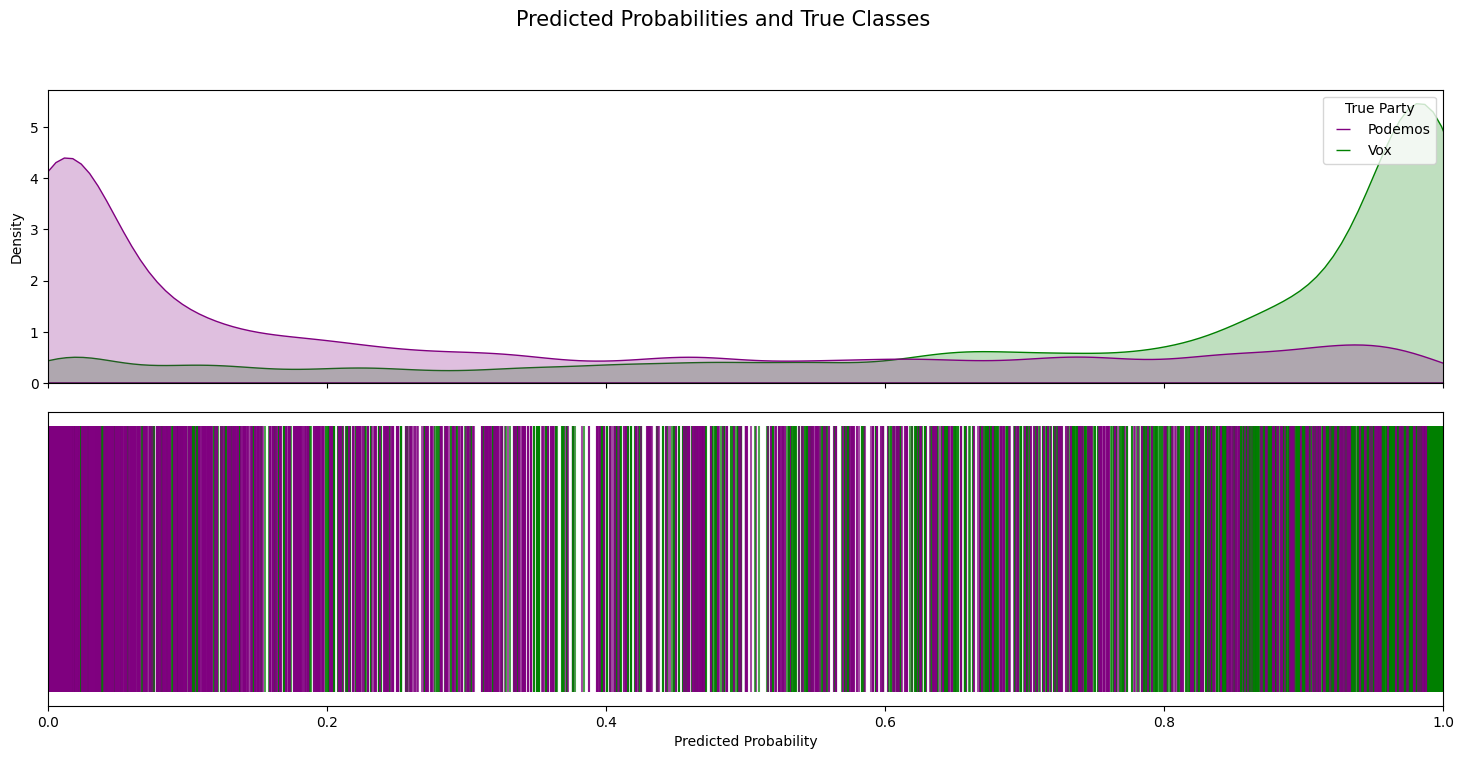
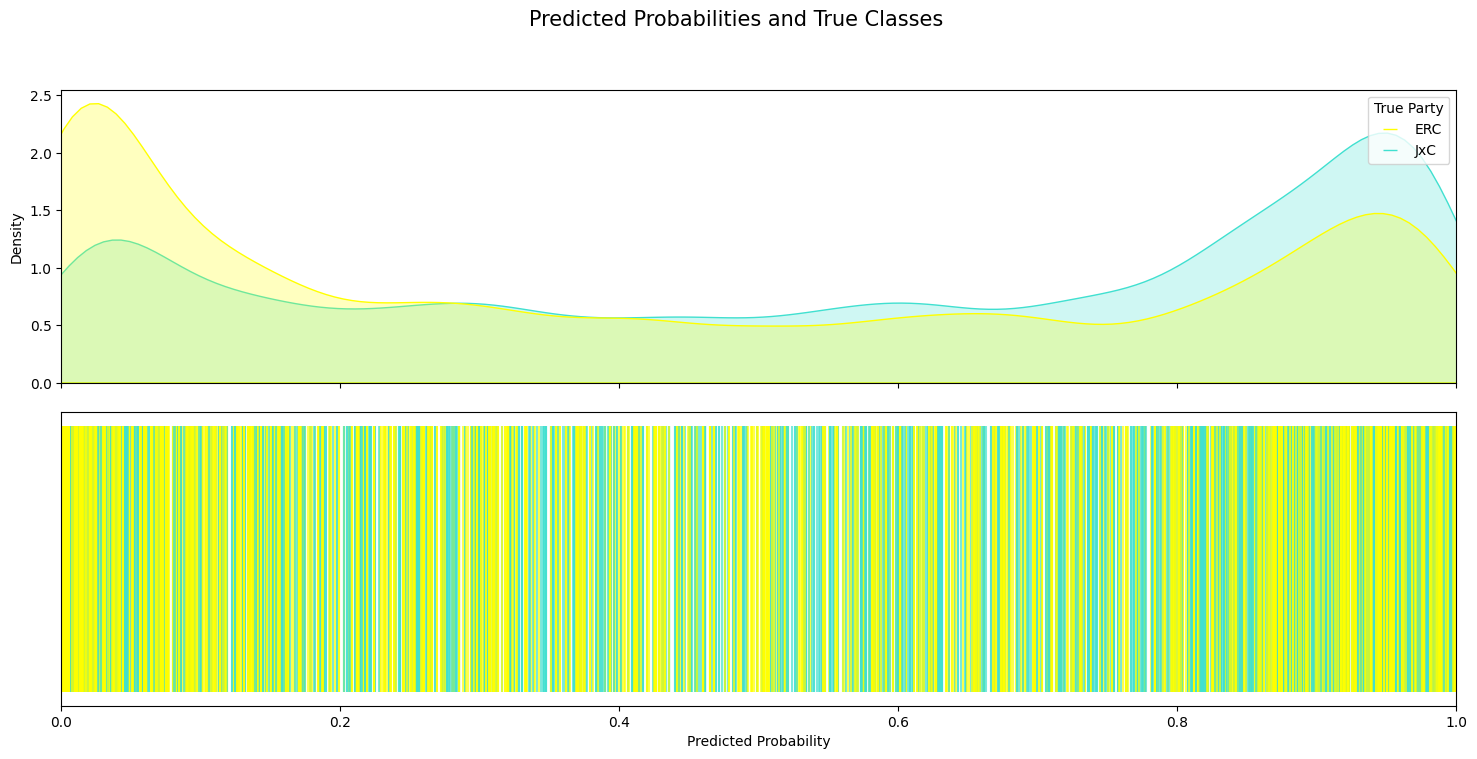
Generalization to Podemos–Vox was particularly successful, yielding an AUC of 0.86. This confirms a semantic continuum within ideological blocks. However, performance dropped for ERC–JxCat and Bildu–PNV, likely due to region-specific discourse not present in PSOE–PP training data. This finding underlines the challenge of modeling regional political identity using national-level rhetorical training.
Podemos-Vox:
ERC–JxCat:
Key Insights and Challenges ✨🧠
- Semantic Consistency: Ideologically similar parties share rhetorical patterns, allowing cross-party generalization.
- Model Robustness: Removing lexical “giveaways” like names and party references improved model generality.
- Domain-Specificity: Regional party rhetoric requires region-specific training data or domain adaptation strategies.
These insights stress the importance of thoughtful data curation and model validation when applying ML in political analysis.
Final Thoughts and Future Directions 🧭📚
This project demonstrates that political ideology is not only present but quantifiable in parliamentary speech. With adequate preprocessing and model selection, it is possible to classify party affiliation with considerable accuracy. Future work could include:
- Incorporating temporal dynamics to analyze discourse evolution.
- Fine-tuning transformer-based models (e.g., BERT) on political corpora.
- Expanding to multilingual or cross-country parliamentary data for broader applicability.
In sum, the project shows that machine learning and NLP are not just capable of detecting ideological lines—they can also provide meaningful insights into how these lines are drawn through language. 🧾📢📐